

目录
快速导航-

情报理论与前瞻观点 | 数智赋能推进敏捷化应急情报体系研究
情报理论与前瞻观点 | 数智赋能推进敏捷化应急情报体系研究
-
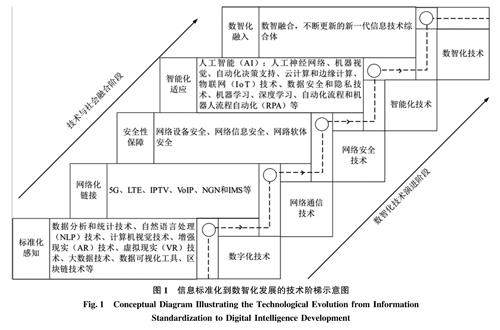
情报理论与前瞻观点 | 数智信息生态系统:内涵、构成与机制
情报理论与前瞻观点 | 数智信息生态系统:内涵、构成与机制
-
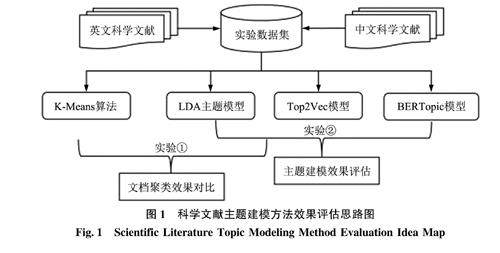
情报分析与技术创新 | 科学文献主题建模方法及其效果评估研究
情报分析与技术创新 | 科学文献主题建模方法及其效果评估研究
-
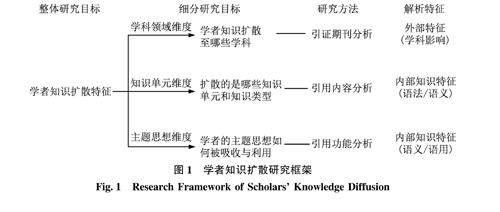
情报分析与技术创新 | 基于引用内容分析的学者知识扩散特征研究
情报分析与技术创新 | 基于引用内容分析的学者知识扩散特征研究
-
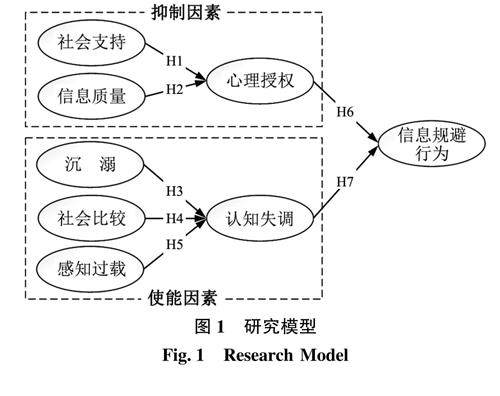
信息行为与用户研究 | 社交媒体用户信息规避行为研究
信息行为与用户研究 | 社交媒体用户信息规避行为研究
-
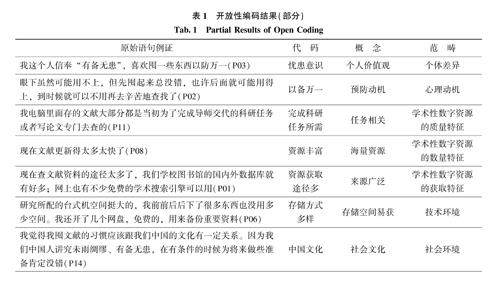
信息行为与用户研究 | 研究生学术性数字囤积行为的影响因素及后果
信息行为与用户研究 | 研究生学术性数字囤积行为的影响因素及后果
-
信息管理与知识管理 | 信息链视域下电子病历数据驱动临床决策的需求模型构建
信息管理与知识管理 | 信息链视域下电子病历数据驱动临床决策的需求模型构建
-

信息管理与知识管理 | 教育学领域学者数据重用行为及特征研究
信息管理与知识管理 | 教育学领域学者数据重用行为及特征研究
-
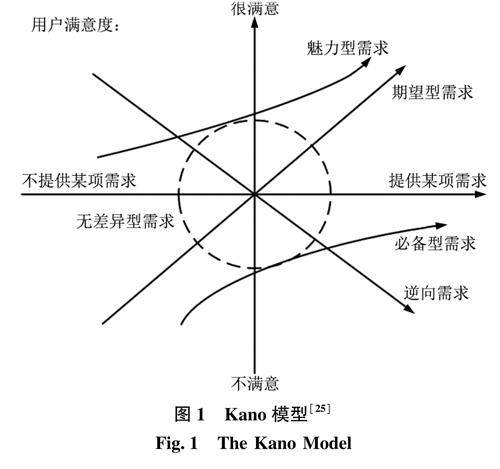
情报业务与情报服务 | 用户需求视角下医疗健康类APP适老化改造内容优先序研究
情报业务与情报服务 | 用户需求视角下医疗健康类APP适老化改造内容优先序研究
-

情报业务与情报服务 | 多源自媒体资源知识组织模型构建研究
情报业务与情报服务 | 多源自媒体资源知识组织模型构建研究
-

信息计量与科学评价 | 基于主题演化动态情境的高被引论文影响力形成模式探索
信息计量与科学评价 | 基于主题演化动态情境的高被引论文影响力形成模式探索
-
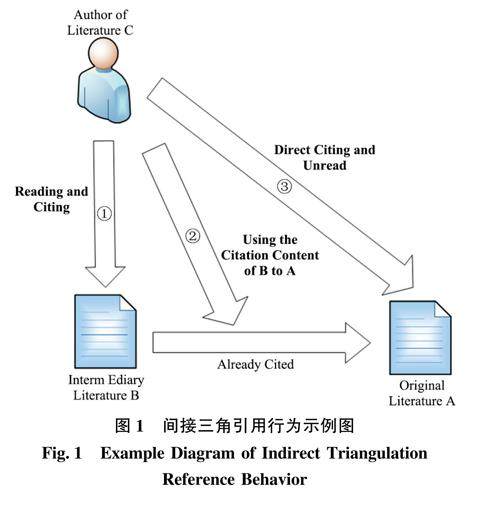
信息计量与科学评价 | 隐形三角引用:科学论文中的不规范引用行为
信息计量与科学评价 | 隐形三角引用:科学论文中的不规范引用行为
-

信息计量与科学评价 | 编委对期刊研究主题的影响研究
信息计量与科学评价 | 编委对期刊研究主题的影响研究
-

研究综述与前沿进展 | 基于LDA-Word2vcc的图书情报领域机器学习研究主题演化与热点主题识别
研究综述与前沿进展 | 基于LDA-Word2vcc的图书情报领域机器学习研究主题演化与热点主题识别
-
研究综述与前沿进展 | 政策文献量化研究中的PMC指数模型应用述评
研究综述与前沿进展 | 政策文献量化研究中的PMC指数模型应用述评





















 登录
登录